Activity
表里如一,知行合一,能量因此觉醒

天边 发了新动态 4天, 21小时 前
elicenser激活码如何获取

Weixin Gateway 升级后连接故障修复方案
📋 问题描述
Herms 系统升级后,Weixin 网关无法连接,Gateway 启动失败。🔍 错误信息
ERROR: weixin: open policy without allow-all opt-in
– Weixin 的 `dm_policy/group_policy` 设置为 `’open’`
– 缺少必需的用户授权环境变量✅ 解决方案日志
步骤 1:检查当前 Gateway 状态
cat /Users/xbaby/.hermes/gateway_state.json
输出显示:gateway_state: “startup_failed”步骤…[查看更多]
-
把上面的参数设置好了就足够训练lora了,参数已经非常全了,目前没有观察到需要设置其他的参数。
大佬,其它参数设置有吗?
-
macOS系统中微信等软件已授权截图与录像权限,但使用时仍反复弹出授权请求。
排查过程:尝试通过Codex环境自动检测,但因底层执行器故障(无法启动shell进程),未能直接读取或修改系统授权数据库。
原因分析:典型TCC隐私授权记录卡死、应用路径/签名变更,或tccd服务缓存异常。
修复步骤(已指导用户手动执行):
1. 完全退出微信及相关截图/录屏工具。
2. 打开终端,执行重置命令:
/usr/bin/tccutil reset ScreenCapture
/usr/bin/tccutil reset Microphone
(若仅针对微信,可执行:/usr/bin/tccutil reset ScreenCapture com.tencent.xin…[查看更多] -
acestep.cpp:跨平台本地AI音乐生成引擎(GGML + C++实现)
官方仓库GitHub – ServeurpersoCom/acestep.cpp
开发语言:C++ (C++17 标准)
核心框架:GGML
技术定位:ACE-Step 1.5 推理后端 / 离线音频生成引擎
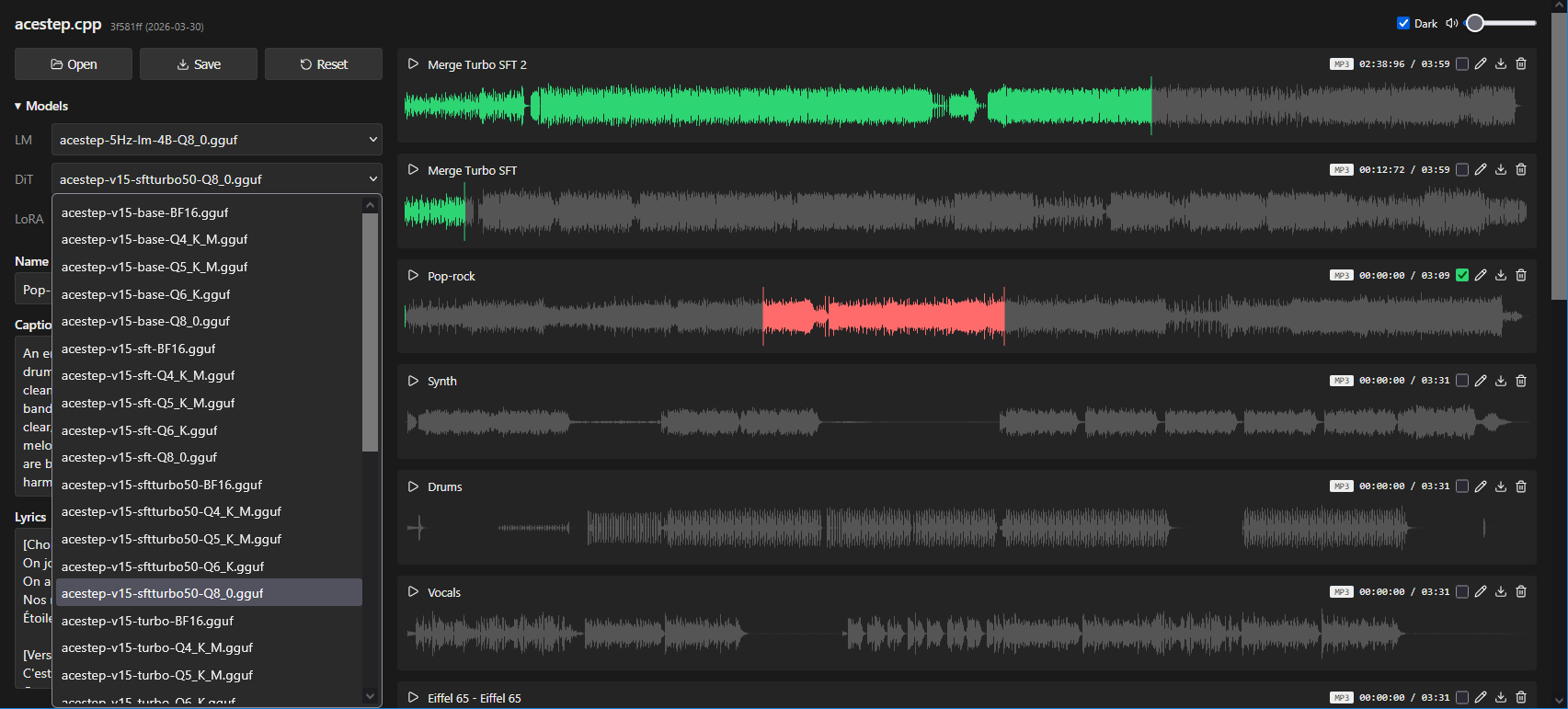
acestep.cpp 是一个基于 GGML 的跨平台本地 AI 音乐生成引擎,使用 C++17 实现 ACE-Step 1.5 推理后端,可在 CPU、CUDA、Vulkan、Metal、ROCm 等多种硬件上运行。项目支持文本生成音乐、歌词生成、音频合成与翻唱等功能,并提供完整 WebUI 与 HTTP API 服务。
用户只需输入音乐描述或歌词,…[查看更多]
请教老师,在DRAW THINGS中使用FLUX-2 KIEIN 9B 8-BIT想制作图生图产品图,如何 设置,能指导一下不.谢谢。
-
使用 agent 时,最好先把目标拆解成清晰的步骤,并提前规划任务流程,例如输入、处理、输出与验证,而不是只下达简单指令。结构化的任务规划可以减少反复修改,提高执行效率,并让模型更准确地理解需求,从而得到更稳定和可控的结果。
在使用 Agent 进行复杂任务时,很多人习惯直接输入一句简单指令,例如“帮我生成一个AI音乐项目介绍”或“写个安装教程”。这种方式虽然方便,但往往会导致结果不稳定,需要多次修改。
以acestep.cpp的文档整理为例,如果采用简单指令,Agent 可能只会输出一段泛化描述,缺少结构、重点不清晰,甚至遗漏关键功能。
而如果采用任务规划方式,效果会明显不同。可以先将任务拆解为四个步骤:
-
AI 大模型省 Token 技巧大全:9 个降低 API 成本与提升效率的方法
尽可能使用 CLI、规划任务、减少不必要的 Skill”非常切中要害,这些都是针对 Multi-Agent(多智能体,如 OpenAI Swarm 等框架)或自动化工作流的优秀优化策略。
在实际开发和调教大模型(尤其是多智能体/Swarm 架构)时,还可以从以下几个维度把 Token 压到极致:
4、善用 Prompt Caching(提示词缓存)
做法: 现代大模型(如 DeepSeek、GPT-4o)都支持缓存。在编写 System Prompt 或工具描述时,保持头部内容完全一致。
效果: 命中缓存的输入 Token 价格能打 1~2 折,能极大…
-
追光 在版块 NewVFX官方发布 ✅ 中回复了话题 《NewVFX架构说明及历程》不敢自满但无比自信 1个月, 3周 前
2026年3月-6月11日:北京、朝阳。今年,我将主要精力聚焦于AI模型在内容与具体服务场景中的深度应用,而非对NewVFX进行更多的底层开发。
在技术学习方面,我着重掌握了SD系列模型,大幅提升了图片创作与精细化编辑的能力;同时,深入探索了Step ace 1.5模型在音乐制作上的潜力,并熟练应用了TTS(文本转语音)及Whisper(语音识别)等模型,有效打通了多模态内容生成的链路。
在业务实践上,我将大量时间投入到Agent(智能体)的应用落地中,致力于通过AI Agent优化具体服务流程,提升内容产出的效率与交互体验。这一策略转变让我更贴近实际业务需求,也为未来NewVFX的智能化服务升级积累了宝贵的实践经验。

林肯公园 – 完整黑暗交响乐翻奏版,适合工作和学习 | 灵感源自维瓦尔第、巴赫和帕格尼尼,带来前所未有的体验。每首歌曲都以电影配乐般的管弦乐编 […]


这部完全由AI生成的科幻奇幻动作短片讲述了地球般星球被神秘巨型怪物入侵的故事。半机械刀客Nino Kuro与魔法师Scarecrow组成不稳定的联盟,穿越未知领域寻找神秘的Noctari族群,以阻止怪物的毁灭之力。影片融合古老魔法与高科技武器,呈现空前的武术对决、 […]


这是一支完全由AI创作的超现实视觉音乐短片。从角色设计、场景构建到动态演绎与氛围呈现,均通过生成式AI技术完成。影片以神秘的香料集市为灵感,将藏红花、肉桂、姜黄与烟雾交织成一场介于现实与梦境之间的感官旅程。
随着充满异域风情的电子节拍,人们穿行于“午夜心灵的市场”,抛开沉重与束缚,在金色迷雾中自由舞动。香气化作节奏,记忆化作火焰,过去与未来在律动中交汇。这里没有语言,只有情绪与共鸣;没有规则,只有舞蹈与想象。
一 […]

-
酷玩乐队 (Coldplay) — 完整黑暗交响乐翻奏 | 灵感源自维瓦尔第、巴赫和帕格尼尼,带来前所未有的体验。 […]


AceStep-cpp UI 是一款基于 ACE-Step 1.5 模型打造的本地 AI 音乐生成软件,通过 C++ 推理引擎 acestep.cpp 驱动,无需 Python 环境即可完成 AI 作曲、歌词生成和音乐创作。与依赖云端服务的 Suno、Udio 等 AI 音乐平台不同,AceStep-cpp UI 支持完全离线运行,用户可 […]

-
对应M1至M5系列芯片的性能数据: Llama 7B 模型在不同量化精度下的性能测试数据
Apple M系列芯片 Llama 7B 性能对比表1. M1系列 (第一代Apple Silicon)
型号
GPU核心
内存带宽 (GB/s)
F16 PP (t/s)
F16 TG (t/s)
Q8_0 PP (t/s)
Q8_0 TG (t/s)
Q4_0 PP (t/s)
Q4_0 TG (t/s)
M1
8
68
–
-
在人工智能和大语言模型(LLM)爆火的今天,无论是开发者还是普通用户,都不可避免地遇到一个词Token(令牌/词元)。买 API 额度时,商家按“每百万 Token”开价;和 AI 聊天时,界面会提示“上下文 Token 限制”。那么,这个神秘的 Token 究竟是什么?它是怎么来的?又是如何决定你钱包里银子流向的?今天我们就来彻底扒一扒大模型背后的这套“硬通货”。
一、 Token 的由来:AI 是如何“识字”的?
要理解 Token 的由来,首先要明白一个底层逻辑:计算机本质上是个“数学脑袋”,它根本不认识人类的文字。
无论是汉字、英文单词、数字还是标点符…[查看更多]
-
如果你正在寻找一种能够生成“电影级史诗音乐”的 AI 音乐模型,那么 ACE-STEP Epic Music LoRA 会是非常值得收藏的一款风格扩展,这是一个基于 ACE-Step 训练的 Epic Music 风格 LoRA,主要强化 Trailer Music、Cinematic Orchestral、Hybrid Orchestra 与大型史诗氛围音乐方向。
加载后,模型会明显增强:电影感配乐,大型交响 […]

-
ACE-STEP-1.5 Techno Rain LoRA 下载|雨夜 Cyberpunk Techno AI 音乐风格模型,如果你正在寻找一种能够生成“雨夜氛围感电子音乐”的 AI 音乐风格模型,那么这个 ACE-STEP-1.5 Techno Rain LoRA 会非常适合你。这是一个基于 ACE-Step 1.5 训练的音乐风格 LoRA,整体方向偏向 Dark Techno、Atmospheric Trance […]

-
这些参数是控制acestep.cpp(Turbo 模型) AI 音乐生成效果的核心“旋钮”。下面拆解这些参数的物理含义和调整建议。
一、 DIT FLOW MATCHING (DiT 扩散模型参数)
这是决定“声音质量”的引擎。
Inference Steps (推理步数)
意义:扩散模型去噪的次数。步数越多,细节越细腻,但越耗时。
Turbo 模型建议:官方预设是 8,你设为 12 是合理的,能稍微增加一点稳定性。不需要过高,否则反而可能产生噪音。Guidance Sca…[查看更多]
-
追光 在版块 Hermes Agent 实际使用案例 中发起了话题 Hermes Agent 实际使用案例 2个月, 1周 前
📖 目录
- [初始设置案例](#初始设置案例)
- [日常开发工作流](#日常开发工作流)
- [消息平台集成](#消息平台集成)
- [多环境管理案例](#多环境管理案例)
- [故障排查案例](#故障排查案例)
- [高级用法案例](#高级用法案例)
初始设置案例
案例 1: 首次安装和配置
bash
# 步骤 1: 安装
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash# 步骤 2: 进入安装目录
cd ~/.hermes/herm…[查看更多] - 查看更多
是什么系统的 Elicenser,若干系统都需要购买正版后会得到license。