【Nuke节点】机器学习CopyCat数据训练节点的参数及功能
› VFX大学 › Nuke合成影视制作 › 【Nuke节点】机器学习CopyCat数据训练节点的参数及功能
-
作者帖子
-
-
2021-03-23 - 11:52 #82061
大家好,Nuke13从一推出就引起全球制作领域的高度关注,除了渲染引擎、远程协作方面的进步外,其最重要的一个功能 CopyCat引起了广泛的谈论与实践,这里刚好解释下 Copycat 可不是“复制猫”的意思噢,为了准确理解这个意思,特地查了 Wiki:

Copycat:
一般解释:山寨、模仿者。指与其他人一样采用,复制,模仿,模仿或遵循相同事物的人。
在计算机领域指:可以进行类比的计算机模型Copycat(软件)。
在科学领域:Copycat是2001年出生的第一个克隆宠物。这个节点叫做:机器学习神经网络,可能更能表达其实质能力。
主要用途:
这个节点实际不仅仅是模仿的概念,其核心是基于人工智能的神经网络训练机器学习,可以通过训练让这个节点学习视频中的图形(人或者物),最终进行提取视频中的物体,即Roto、或替换类似部分的物体。
今天分享的这部分,仅仅用来学习这个节点的参数控制以及输入输出流程。
-
2021-03-23 - 13:37 #82063
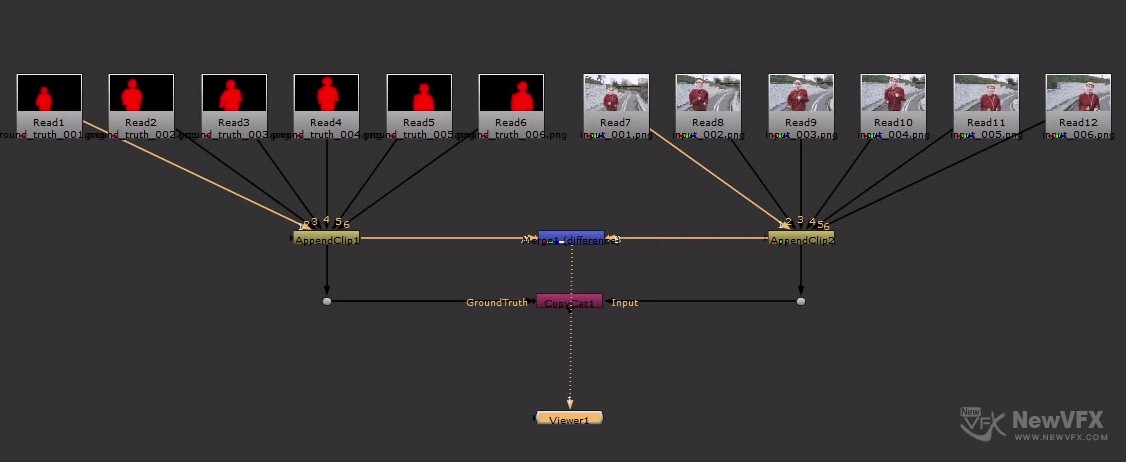
CopyCat 节点的三个输入端口及功能

CopyCat(仅适用于NukeX和 Nuke Studio)可以从一段视频的几个关键帧中学习某种数据,比如Roto,美容修复或去模糊,通过训练神经网络,可以将这些数据应用到整个视频中。CopyCat在.cat文件中输出经过训练的网络数据集,以供推理节点使用这些数据。
Input(输入端):应用任何效果之前的图像序列。
Ground Truth(处理后的数据):应用所需效果后的图像序列。此输入描述了网络正在尝试学习的内容。
Preview(预览):可选的示例图像叠加层。此输入用于查看模型应用于帧(该帧不属于用于训练模型的数据集的一部分)时的工作方式。随着训练的进行,“预览”图像应朝着“地面真相”所定义的理想结果移动。注意:仅当输入和地面真相连接时,Preview(预览)端口此输入才可见。
-
2021-03-23 - 13:52 #82065
Copycat 机器学习节点控制器的参数及功能

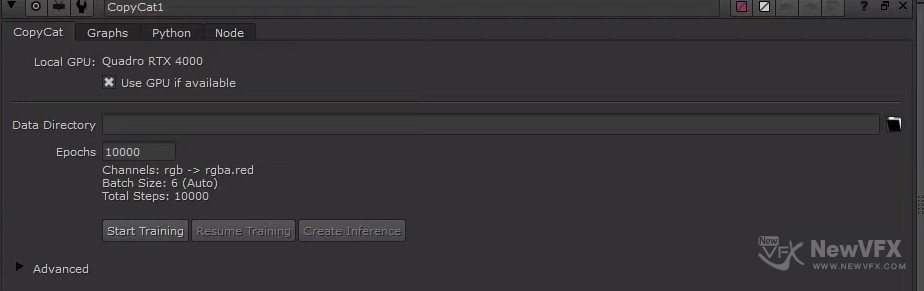
1、本地GPU(gpuName):默认不启用
启用“使用GPU”(如果可用)时显示用于渲染的GPU。本地GPU显示在以下情况下不可用:
•在“首选项”中,将“使用CPU”选择为默认的渲染设备。
•在系统上找不到合适的GPU。
•无法创建用于在所选GPU上进行处理的上下文,例如,当GPU上没有足够的可用内存时。
可以选择另一个GPU(如果有),方法是在“首选项”,从默认设备下拉列表中选择一个替代的GPU ,选择其他GPU要求您重新启动Nuke才能使更改生效。
使用GPU(如果有)useGPUIfAvailable:勾选后将会启用,启用后,渲染将在指定的本地GPU(如果有)上而不是CPU上进行。
2、资料目录(dataDirectory):默认为空,需要手工选择目录,选定后CopyCat表和.cat文件将会输出到此目录下。
3、精度(epochs):默认为10000,设置后在训练网络期间CopyCat处理整个数据集的次数。较高的值通常会产生更高精度的结果,但是会花费更长的处理时间。
4、显示信息,可在高级选项中自定义
通道数(Channels):神经网络模型要处理的通道信息。默认情况下,Batch Size(批次大小)是使用可用的GPU内存自动计算的。
Batch Size(批量大小):CopyCat都会使用输入和结果图像信息除以“批次大小”中的随机作物对来训练网络。
Total Steps = Epochs * (Data Set Size) / (Batch Size)
Total Steps(总步数):完成指定数量的精度所需的步骤数,总步数=精度*(数据集)/(批处理大小)。
Crop Size(裁切大小):定义从数据集图像对中获取解算部分的大小。较大的值通常会产生更准确的结果,但是会消耗更多处理时间和内存为代价,而较小的值可能需要更多的迭代尝试才能产生良好的结果。 在我们的测试中,默认256适用于大多数场景,但较大图像的数据集可能需要较大的参数才能有效训练。
Checkpoint Interval(检查点间隔):设置保存到数据目录中的每个检查点.cat文件之间的步数。 可以将.cat文件加载到推理节点中,以在整个序列上的检查点查看训练进度。
5、开始训练(startTraining):单击以开始使用当前设置训练网络。
继续训练(Resume Training):单击后会从数据目录中记录的检查点再次重复训练。
建立推论(Create Inference):在训练完毕后,单击将一个Inference(推理节点)添加到“节点图”,该节点会自动引用此CopyCat节点的生成的.cat文件。
Graphs Tab
Log Scale(对数刻度):启用后,图形y轴将从线性转换为对数,随着训练的深入,它可以较低的值显示更多详细信息。Smoothness(光滑度):显示指定数据目录中所有训练的步数/损失数据。 可以使用曲线通过图表上方的缩放控件实时监视训练。
Runs(运行):显示指定目录中所有在运行训练的数据。 可以使用每个条目左侧的复选框启用和禁用曲线以分别运行。还可以通过双击“名称”字段并输入自己的字符串来重命名“数据目录”中的文件。
Python选项卡(这些控件用于Python回调,可用于在Nuke中发生各种事件时自动调用Python函数。)
before render(渲染前):这些函数在开始执行execute()之前运行。如果它们引发异常,则渲染中止。
after each frame(每帧之后):这些功能在开始渲染每个单独的帧之前运行。如果它们引发异常,则渲染中止。
after each frame(每帧之后):这些功能在每帧渲染完成后运行。如果渲染异常终止,则不会调用它们。如果它们引发异常,则渲染中止。
after render(渲染后):这些功能在所有帧的渲染完成后运行。如果他们抛出错误,则渲染中止。
render progress()这些功能在渲染过程中运行以确定进度或失败。
-
-
作者帖子

- 在下方一键注册,登录后就可以回复啦。
