VFX小布丁
@VFX小布丁
2天, 5小时 前在线-

4S会自动停止,意味着卡的速度低于内存中的数据需要写入的速度,然后内存满了。
这个速度是卡的速度限制,卡的速度即使是最快的卡,也达不到机器的速度。还可以设置分辨率的裁切比例,帧速率,分辨率来选取一个适合自己配置的设置,另外卡的真实速度和标称速度要实际测试。实际写入速度需要大于100MB/s,可以用大文件拷入进行测试。
比如我的5D3的机器,标配的卡录制2秒就停了,换了雷克沙的高速卡,单镜头能达到4分钟就已经足够使用了,一个镜头一个镜头的拍。Raw的视频包含元数据非常大。我的配置不到20分钟的镜头,64GB卡就满了。
Raw视频适合高标准,有着严格拍摄脚本的广告、剧情一类的制作,不太适合即兴拍摄,因为后期流程也和胶片差不多。适合像拍电影一样的拍,每个镜头都思考好了再开始,很像胶片拍摄的流程。
-
MLV.App功能强大,界面清晰,更新速度非常快,更加符合现代化的制作方式。MlRawViewer是最早期的制作人拍摄Raw视频的方式,制作方式更加传统,比如默认导出为DNG序列,然后在AE或者达芬奇中进行处理。
魔灯具有自己独立的网格模式,需要在魔灯菜单里面设置,当然还有更多佳能官方没有的模式,包括峰值对焦之类,可以从社区内菜单的翻译上查看更多功能,我比较常用的是延迟拍摄、峰值对焦、还有低帧速率视频。和佳能的网格模式相当于是俩个不同的操作系统,不可以混用。
-
你好,本篇文章讲述的就是如何直接将3DEqualizer计算好的畸变数据作为一个独立的节点,直接传输给Nuke,而不需要进行渲染。如果非要渲染出来作为参考视频导入到三维软件进行对位测试,在nuke中渲染即可。
可以采用这样的流程:
3DEqualizer—-导出畸变数据到Nuke—-导出去除畸变的素材给三维软件参考使用
三维软件中输出制作好的匹配模型动画—-导出模型或者渲染图—-导入到Nuke—-添加3DEqualizer畸变。这样即可让三维渲染保持和原始视频一致的畸变,更加真实。
-
Ableton Live 12.2中的新功能
1、生成音频到新轨道
现在,只需点击几下,就可以将任何MIDI或音轨(包括所有处理)上的片段生成为音频到新的音轨上,或使用Bouce轨道就位将整个音轨转换为音频。
提示:这个功能在多年前的logic上就有,非常好用。
2、自动过滤器
Ableton live的核心音频效果——但它在12.2中听起来和看起来都像新的一样。尝试Vowel、DJ和Comb等创意滤波器类型,并借助Auto Filter的改进调制部分、新的混音控制和实时可视化,以更高的精度塑造声音。汽车过滤器也将在今年晚些时候出现在Move and Note上。
3、Expressive Chords
支持MPE的Max for Live设备,适…[查看更多]
-
追光 在版块 拍电影-拍摄经验分享社区 中回复了话题 【科学基础】光的平方反比定律的数学表达式 4天, 23小时 前
📸 摄影棚中《光的平方反比定律》的实践应用详解
在摄影棚环境中,光的平方反比定律 是控制布光强度、塑造氛围和精准曝光的重要理论依据。无论是棚拍人像、产品摄影还是视频布光,该定律都能为你提供清晰可控的技术支撑。
什么…[查看更多]
-
追光 在版块 拍电影-拍摄经验分享社区 中发起了话题 【科学基础】光的平方反比定律的数学表达式 5天, 20小时 前
光的平方反比定律,就像牛顿的力学定律一样,光也遵循着特定的定律。光的平方反比定律描述了光强随距离增加而成平方反比衰减的物理规律,广泛应用于摄影、照明、光学设计等领域。本文提供公式解析、图示说明及实用计算方法,助你精准掌握光强与距离之间的关系。
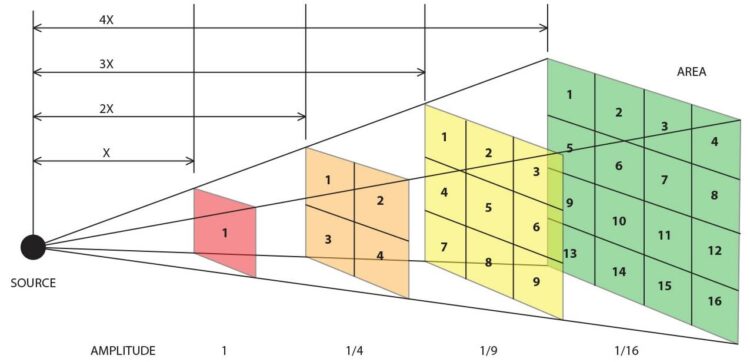
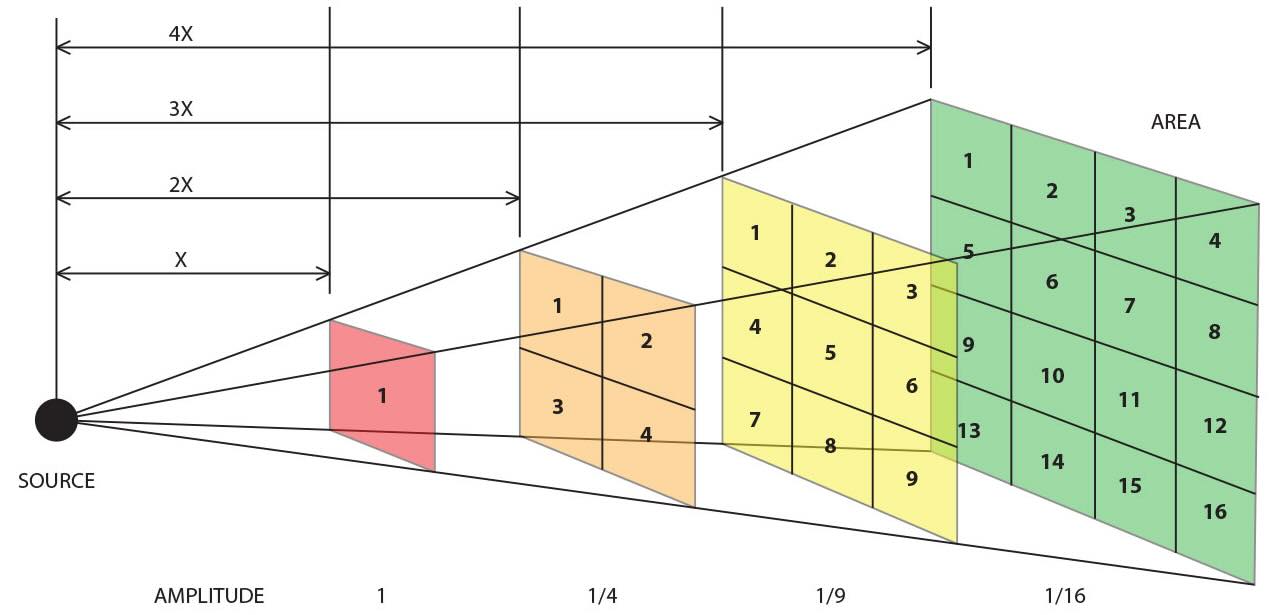
光的平方反比定律描述了光强度随着距离增加而减弱的规律,具体来说:
数学公式
光强度 I 和距离 d 的关系为:其中:
I:光强度(单位:流明或勒克斯,具体取决于应用场景)
P:光源发光总功率(单位:流明)
d:光源到目标点的距离(单位:米)对于摄影中的灯光距离和镜头光圈的调整,公式可以简化为:
-
追光 在版块 Logic,Cubase电影音乐制作社区 中回复了话题 【科学基础】声音的物理本质与能量的基本数学表达式 6天, 4小时 前
EQ(Equalization,均衡器)本质上是一个频率选择性的增益函数:
频谱图(如 Ableton 的 Spectrum、FabFilter 的 Analyzer)实时显示 X(f);EQ 滤波器实际影响的是 H(f);混音时,我们观察频谱并视觉定位问题频段,然后手动绘制 H(f) 来进行补偿或增强。
EQ 不是“修音”,是“重塑频率能量分布”,本质是用数学曲线,对声音进行“能量雕刻”。
它作用于信号的频谱,在特定频率区域 放大(Boost) 或 削减(Cut) 能量。
-
追光 在版块 Logic,Cubase电影音乐制作社区 中发起了话题 【科学基础】声音的物理本质与能量的基本数学表达式 6天, 4小时 前
声音是“机械纵波(Mechanical Longitudinal Wave),是一种在介质…[查看更多]
-
追光 发了新动态 6天, 14小时 前
鉴于 Waves 插件在混音中的行业标准的地位,以及发展到今天,全球绝大多数专业录音棚、广播电视台、现场演出系统里,都能看到 Waves 插件的身影。以前曾经潦草的写过waves推荐的15个插件的推荐简介浏览量超过10W,随着插件更新,针对每个插件的介绍以及核心功能又重新写了一遍:
-
追光 在版块 VFX Pipeline | 数字创意工作流 中回复了话题 Ai应用RAG知识库构建与部署资源使用方法汇总 1周, 4天 前
Pinecone向量数据库的在线使用方法
Pinecone 是一个专为机器学习和人工智能应用设计的托管向量数据库服务。它主要用于存储、检索和管理高维向量数据(如嵌入向量),并支持高效的相似性搜索(Similarity Search)。Pinecone 的核心目标是帮助开发者轻松构建和部署基于向量的应用程序,例如推荐系统、语义搜索、异常检测等。
1. 登录并创建项目
访问 Pinecone 网站:打开 [Pinecone 官网]并登录账户。
进入仪表板:成功登录后,将看到一个仪表板界面。
创建新项目:在免费层级(Free Tier)下启动一个新项目。点击“创建项目”按钮,并为项目命名。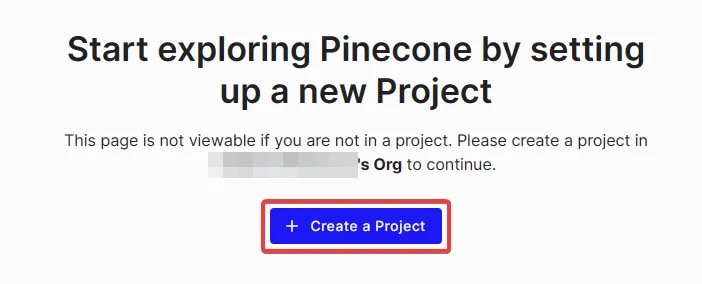
2. 获取 API 密钥…[查看更多]
-
追光 在版块 VFX Pipeline | 数字创意工作流 中回复了话题 Ai应用RAG知识库构建与部署资源使用方法汇总 1周, 6天 前
Qdrant向量数据库部署方法以及使用方法
Qdrant 是一个高性能的向量搜索引擎,专为存储和检索高维向量数据而设计。它支持语义搜索、推荐系统、图像检索等应用场景。Qdrant 提供了开源版本以及在线托管服务(Qdrant Cloud),开发者可以轻松部署和使用。以下是 Qdrant 的基本使用流程:
一、安装Qdrant(使用docker安装)
1、拉取静像
docker pull docker.m.daocloud.io/qdrant/qdrant2、运行镜像(在运行前必须要设置api密钥)
docker run -d -p 6333:6333 -p 6334:6334 -e QDRANT__SERVICE__API_KE…[查看更多] -
追光 在版块 VFX Pipeline | 数字创意工作流 中回复了话题 Ai应用RAG知识库构建与部署资源使用方法汇总 3周, 5天 前
3. 向量数据库
向量数据库(Vector Database)用于存储、索引和高效检索 高维向量,常用于 语义搜索、推荐系统、异常检测 等场景。例如,文本、图像、音频都可以转换为向量,以便进行相似性搜索。将数据转换为 嵌入向量,嵌入向量存储与检索。Pinecone 和 Qdrant 进行对比,选择更适合你的 向量数据库需求?
两者都是 高效的向量数据库,但它们有一些关键区别:
Pinecone vs. Qdrant 对比
特性
Pinecone
Qdrant
部署方式
云端 SaaS(Pinecone 提供托管)
本地部署 / 自托…[查看更多]
-
追光 在版块 VFX Pipeline | 数字创意工作流 中发起了话题 Ai应用RAG知识库构建与部署资源使用方法汇总 1个月 前
Ai的发展给更多行业带来了便利,但如何应用到实际工作中成为生产力的一部分也是我一直在思考的问题。通过在api以及本地部署模型,进行前端调用,以及RAG知识库构建、通过大模型训练精微模型,每一种方式我都尝试过。在这个过程中也搜集了一些有用的站点。将这些记录在这里,以后还会继续更新。
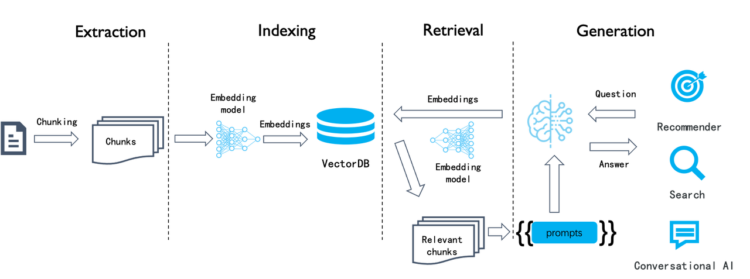
1. 本地部署大模型(LLM)
选择合适的模型:选择适合需求的 LLM
使用Ollama和LM Studio部署各大产商开源模型的流程2、嵌入模型(Embeddings):
生成嵌入向量:使用合适的嵌入模型(如 BERT、Sentence-BERT)将文本内容转化为固定维…[查看更多] -
是可以追踪定机位的,技术流程请参考这一篇:
如果在反求镜头追踪的同时,还需要追踪车辆轨迹,可以使用复合追踪流程:
另外不管是PFtrack还是3DEqualizer都可以导出选择的物体为坐标数据,TXT文本。我以前用这个方法交换不同软件的追踪数据。但是要注意,不同软件的位置标记记录算法比例可能不同。
-
FRPC批量端口号代理与泛域名解析配置方法
这个配置文件是 Frp 客户端(frpc) 配置的一部分,使用了 Go 模板语法 来生成多个代理配置。它的作用是根据 端口范围 来动态生成多个 TCP 代理。接下来,我将详细解释每个部分:
parseNumberRangePair 是一个自定义函数(假设是为了处理端口范围),将字符串 “888-999” 转换为一个端口范围。例如,888到999。
•第一个参数 “888-999” 是表示端口范围的字符串。
•第二个参数 “888-999” 是备用参数或者用于其他配置逻辑。
•range 是 Go 模板的关键字,允许遍历 parseNumberRangePair 返回的… -
各产商的大模型部署并在工作中投入生产使用的大模型选择
这里的测试方面的数据为硬件平台直接输出,而感受与总结方面尽可能做到客观,但难免会有主观之处:
1、除了deepseek开源,还有其他开源大模型么
deepseek是公开发布并可以下载的模型,开源对我们来说是非常有益的事情,同时我们也应关注更多的开源产商LLaMA、Qwen、Mistral,google的开源模型群,微软的、ibm等,每个产商的模型都是成千上万技术人员的劳动成果,通过各种算法集合了人类的智慧,也就决定了不同的大模型具备的核心能力也有所区别,作用用户我们要打开视野,多使用不同的模型,从计算成本、计算效率、结果的可靠性三个方面来选择最适合我们工作流的模型。
未完待进一步补充~~
经过若干测试,对工作…[查看更多]
-
在Mac M1pro上使用lm studio和ollama的感受
1、效率与速度
LM Studio使用GGUF模型比Ollama反应速度更快20%,如果在LM Studio中使用苹果M芯片框架的MLX比GGUF还要快30%,在效率和配置效率方面LM Studio更高效。拿DeepSeek R1:14B执行相同的任务来说
在Ollama上达到,9.34 tokens/s,在LM Studio使用GGUF:13.4 tokens/s,而MLX可以达到18.43 tokens/秒。此外,LM Studio的内存占用也比Ollama低,尤其是在处理大规模数据时,LM Studio的内存占用会更少,这使得它在处理大规模数据时更加高效。
-
在本地部署Deepseek R1等开源模型是今年的热点话题,当然本人使用chatgpt进行代码写作、硬件配置查询已经有俩年多的历史,随着国产Ai的进一步发展,Deepseek已经成为热点话题,当然开源的LLM不只有Deepseek,还有Meta的Llama3,微软的Phi,阿里巴巴的Qwen,Google的Gemma,IBM Research的Granite3,Mistral等开源模型,这些模型都可以本地化部署,私有化使用,并可以构建自己的知识库。
AI模型相当于素材,也相当于弹药,软件即枪械:这些开源大模型如同数字军火库中的新型武器,但要真正发挥威力,需要将模型装载到合适的平台。就像摄影师需要Lightroom处理RAW格式,剪辑师需要Premiere编…
-
我之前遇到了一个问题,就是在使用 Waves 插件的时候,加载预设或者打开插件的速度非常慢。这让我很困扰,因为工作效率受到了影响。后来,找到了一种方法可以通过删除某个特定的文件或文件夹来解决这个问题。
1、定位缓存文件路径:
Mac 用户: 打开 Finder,前往
HDLibraryApplicationSupportWavesWavesLocalServerWindows 用户(通常在 D 盘): 导航到
C:ProgramDataWaves AudioWavesLocalServer2、在路径中找到 WavesLocalServer 文件夹,谨慎地将其删除。此操作不会影响插件功能,但会清除不必要的缓存数据。…[查看更多]
-
追光 在版块 拍电影-拍摄经验分享社区 中回复了话题 佳能EOS相机升级/降级固件的方法流程 2个月, 2周 前
我看你是将固件降级进行安装的,所以你已经进行了一次固件降级到1.2.3(第一次官方固件安装),在将相机固件降级到1.2.3后,还需要再进行魔灯固件的安装,固件的安装需要将解压后的文件复制到相机卡,再次进行安装魔灯(魔灯固件安装)。也就是一共需要安装俩次,确保你已经成功进行了第二步,再进行操作。
-
安装魔灯时没有出现教程里面出现的内容,这是怎么回事?
-
我安装了几次了,用SD卡、CF卡都安过,还是不行!急!急!急!
-
- 查看更多