追光
论坛回复已创建
-
作者帖子
-
-
2025-04-22 - 20:30 #128413

追光参与者Ableton Live 12.2中的新功能
1、生成音频到新轨道
现在,只需点击几下,就可以将任何MIDI或音轨(包括所有处理)上的片段生成为音频到新的音轨上,或使用Bouce轨道就位将整个音轨转换为音频。
提示:这个功能在多年前的logic上就有,非常好用。
2、自动过滤器
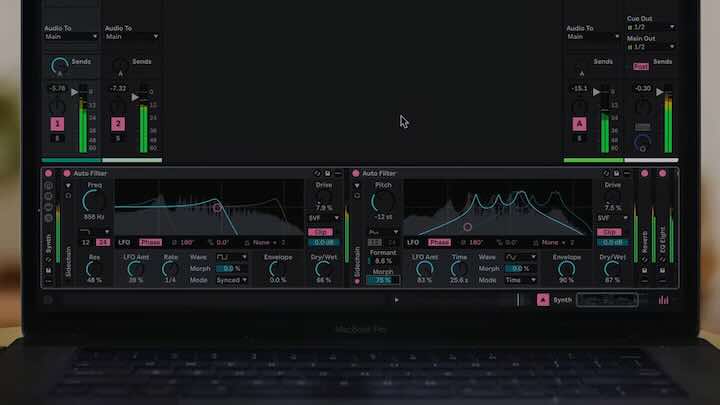
Ableton live的核心音频效果——但它在12.2中听起来和看起来都像新的一样。尝试Vowel、DJ和Comb等创意滤波器类型,并借助Auto Filter的改进调制部分、新的混音控制和实时可视化,以更高的精度塑造声音。汽车过滤器也将在今年晚些时候出现在Move and Note上。
3、Expressive Chords
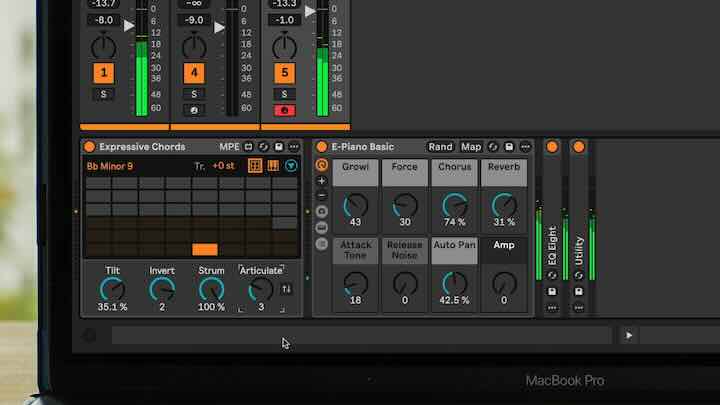
支持MPE的Max for Live设备,适用于Live 12 Intro、Standard和Suite,可一次一个键就直观地探索有趣的和弦和进展。在传统按键和音阶的范围外进行创作,使用听起来不错的东西,并使用MIDI和MPE控件获得更具表现力和自然的结果
4、更轻松地搜索、标记和浏览
Live的浏览器经过重新设计,可更高效地查找和整理内容。新的“快速标签”面板允许直接在浏览器中查看、编辑和分配标签。过滤器视图已经简化,其隐藏功能也变得更加容易被发现。可以使用一系列新图标自定义边栏中任何标签和用户文件夹的外观,浏览器可以同时查看多个元数据列。 -
2025-04-22 - 14:44 #128406
追光参与者📸 摄影棚中《光的平方反比定律》的实践应用详解
在摄影棚环境中,光的平方反比定律 是控制布光强度、塑造氛围和精准曝光的重要理论依据。无论是棚拍人像、产品摄影还是视频布光,该定律都能为你提供清晰可控的技术支撑。
什么是光的平方反比定律?
光的平方反比定律说明:点光源发出的光强度随距离的平方成反比。换句话说,光源离拍摄对象越远,单位面积上的光照强度就衰减得越快。
数学表达:
\(I = \frac{P}{4\pi d^2}\)
- I:目标处的光照强度
- P:光源发出的总功率
- d:光源到物体的距离
📐 应用举例:灯距变化对光强的影响
灯光距离 (米) 相对光强度 1 100% 2 25% 3 11.1% 4 6.25% 这意味着——灯距翻倍,光强变为原来的四分之一;灯距变成原来的一半,光强增强 4 倍。
🎯 实际场景中的应用
1. 布光平衡调整
在拍摄多人物或产品时,你可能需要不同灯照亮不同区域。如果某一盏灯距离目标较远,你可以通过以下方式保持亮度一致:
\(I_1 \cdot d_1^2 = I_2 \cdot d_2^2\)
这个公式允许你在 不改变功率的前提下,通过调节距离 让光照更均衡。
2. 光圈与灯距联动计算
摄影中常见的场景是:你想换光圈或快门速度,但又不想改变画面亮度。这时可以用以下公式计算新的灯距:
\(d_2 = d_1 \cdot \frac{f_2}{f_1}\)
使用举例:
当前光圈为 f/4,灯距为 2 米。
如果你想换成 f/2.8,求新的灯距:\(d_2 = 2 \cdot \frac{2.8}{4} = 1.4 \text{ 米}\)
🔍 解释: 光圈越大(f 值越小),进光量越多,为了维持原来的亮度,灯必须拉近到更短的距离。
3. 控制光感与柔和度
光源越靠近主体:
- 光照越强,对比越大,阴影边缘越硬;
- 适合强调面部结构或塑形质感。
光源越远:
- 光线分布越均匀,阴影边缘越柔;
- 适合拍摄皮肤质感、产品广告或需要柔和光的布光风格。
🔧 棚拍建议小技巧
- 使用柔光箱、反光伞时,光线被扩散,虽然总光量不变,但局部光强降低,仍然受平方反比定律影响。
- 对比观察曝光前后变化,可以拍摄一组固定参数样片,仅调整灯距,观察亮度衰减。
- 搭配 测光表或直方图工具 实时检查光强变化是否符合预期。
光的平方反比定律不仅是一个物理公式,更是摄影棚布光的底层逻辑。
精准控制曝光而无需反复试错;
高效搭建多灯位系统;合理分配主光与辅光的功率与位置;
快速适应不同拍摄需求,提高拍摄效率。 -
2025-04-21 - 09:31 #128328
追光参与者EQ(Equalization,均衡器)本质上是一个频率选择性的增益函数:
频谱图(如 Ableton 的 Spectrum、FabFilter 的 Analyzer)实时显示 X(f);EQ 滤波器实际影响的是 H(f);混音时,我们观察频谱并视觉定位问题频段,然后手动绘制 H(f) 来进行补偿或增强。
EQ 不是“修音”,是“重塑频率能量分布”,本质是用数学曲线,对声音进行“能量雕刻”。
它作用于信号的频谱,在特定频率区域 放大(Boost) 或 削减(Cut) 能量。
在数学上:
一个 EQ 可以看作是一个 线性时不变系统(LTI),其效果可用卷积描述:
y(t) = x(t) * h(t)其中:
x(t) 是输入信号
h(t) 是 EQ 的脉冲响应
* 表示卷积运算
y(t) 是处理后的输出信号
频谱角度看 EQ
信号的频谱是通过 傅立叶变换(Fourier Transform) 获得的:
X(f) = ∫ x(t) * e^(-j2πft) dt应用 EQ 实际上就是将一个频谱 X(f) 乘以一个频率响应 H(f):
Y(f) = X(f) × H(f)换句话说:EQ 就是在频域上进行的乘法滤波,每个 EQ 滤波器类型对应一个特定形状的频率响应 H(f)。
-
2025-04-16 - 10:31 #128259
追光参与者Pinecone向量数据库的在线使用方法
Pinecone 是一个专为机器学习和人工智能应用设计的托管向量数据库服务。它主要用于存储、检索和管理高维向量数据(如嵌入向量),并支持高效的相似性搜索(Similarity Search)。Pinecone 的核心目标是帮助开发者轻松构建和部署基于向量的应用程序,例如推荐系统、语义搜索、异常检测等。
1. 登录并创建项目
访问 Pinecone 网站:打开 [Pinecone 官网]并登录账户。
进入仪表板:成功登录后,将看到一个仪表板界面。
创建新项目:在免费层级(Free Tier)下启动一个新项目。点击“创建项目”按钮,并为项目命名。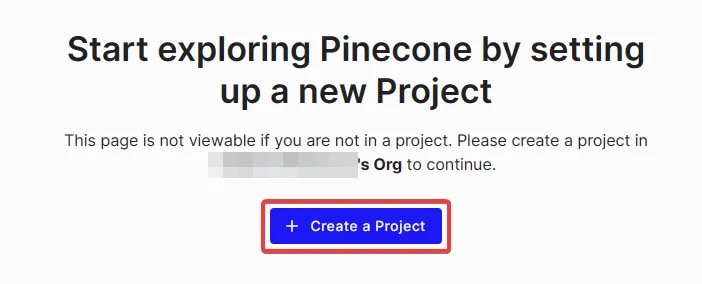
2. 获取 API 密钥
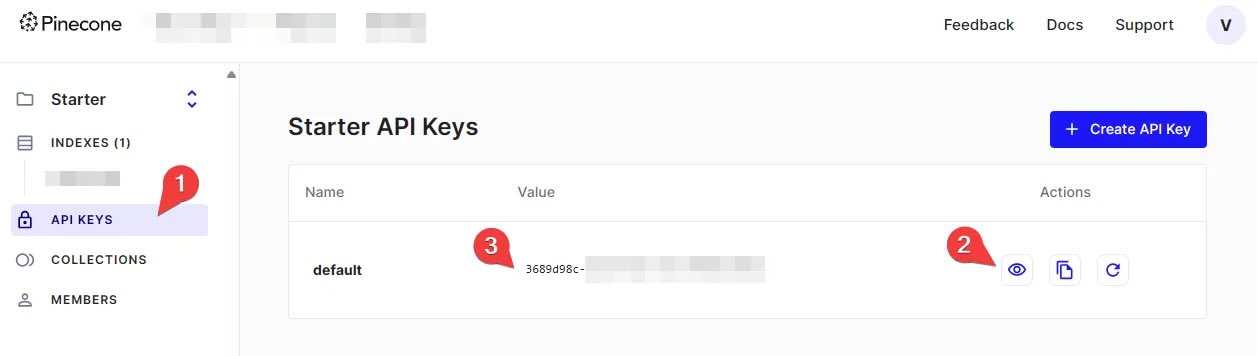
导航到 API 密钥选项卡:在仪表板中找到并点击“API 密钥”选项卡。
检查默认密钥:如果已经有一个名为“默认”的 API 密钥,则可以直接使用它。如果没有,点击“创建 API 密钥”按钮生成一个新的密钥。
显示并复制密钥:点击眼睛图标(👁️)以显示密钥的值,然后将其复制并妥善保存。这个密钥将在后续步骤中用于身份验证。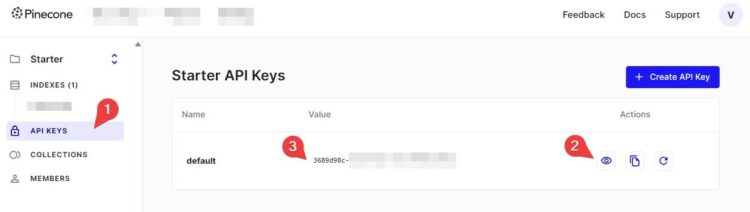
3. 创建索引
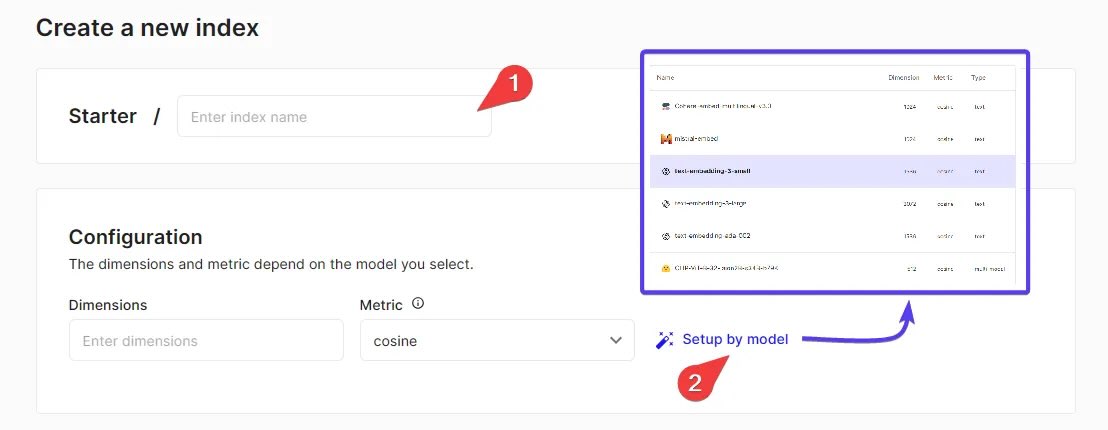
选择索引名称和维度:在仪表板中,点击“创建索引”按钮。为索引指定一个名称,并设置其维度(Dimension)。
注意:索引的维度应与您在 AI 引擎设置中的嵌入向量维度相匹配。例如,在“AI 默认环境 > 嵌入”中找到嵌入模型的维度,并确保它们一致。
选择配置选项:使用“按型号设置”选项,根据需求选择合适的配置(如性能模式、Pod 类型等)。
完成创建:确认设置后,点击“创建”按钮以生成索引。
4. 获取主机值
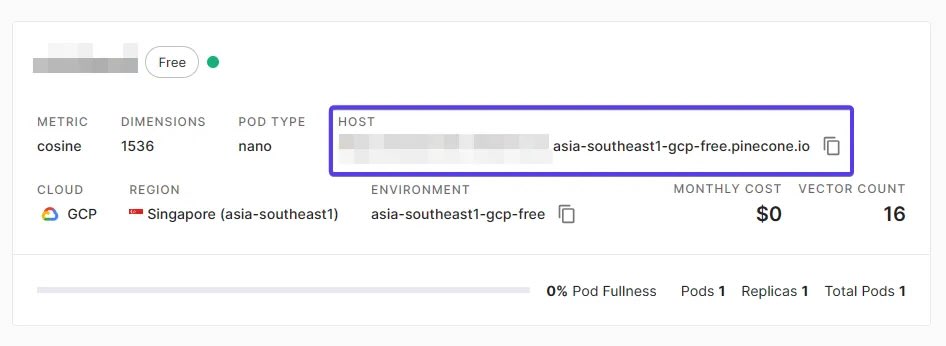
查找主机地址:在索引创建完成后,可以从仪表板中找到该索引的“主机”(Host)值。
记录主机值:将主机值复制下来,因为需要在 AI 引擎中使用它来连接到 Pinecone 服务。
-
2025-04-14 - 10:14 #128251
追光参与者Qdrant向量数据库部署方法以及使用方法
Qdrant 是一个高性能的向量搜索引擎,专为存储和检索高维向量数据而设计。它支持语义搜索、推荐系统、图像检索等应用场景。Qdrant 提供了开源版本以及在线托管服务(Qdrant Cloud),开发者可以轻松部署和使用。以下是 Qdrant 的基本使用流程:
一、安装Qdrant(使用docker安装)
1、拉取静像
docker pull docker.m.daocloud.io/qdrant/qdrant
2、运行镜像(在运行前必须要设置api密钥)
docker run -d -p 6333:6333 -p 6334:6334 -e QDRANT__SERVICE__API_KEY=密钥 -v /挂载的磁盘路径/:/qdrant/storage --name NewVFX_Vector docker.m.daocloud.io/qdrant/qdrant:latest
3、默认在 localhost:6333 运行
打开浏览器输入地址后即可打开管理界面,这里会弹出密钥验证,输入运行时候设置的密钥即可。
4、创建数据库
PUT collections/star_charts { "vectors": { "size": 1024, "distance": "Dot" } }//star_charts 是数据库名(随意更改),size是数据库维度,不同的Emb模型有不同的数据维度;distance是计算方式。
5、创建好数据库后,在应用内连接
服务器:localhost:6333 ;数据库名:star_charts;apikey:密钥
6、数据库的备份和还原
Qdrant支持数据库快照,可以将数据库打快照并下载备份,也可以上传快照进行还原。点击进入数据库后,点击Snapshot,即可创建快照并下载。也可以在collection界面上传快照对数据进行还原。
二、 Qdrant 在线托管数据库的使用方法
Qdrant Cloud 提供完全托管的在线数据库服务,无需管理底层基础设施。自动扩展功能,适应不同规模的工作负载。
以下是使用 Qdrant 托管数据库 的详细步骤:
1. 访问 Qdrant Cloud,并注册一个新账户。
2. 创建集群
登录后进入控制台 ,将看到 Qdrant Cloud 的管理界面。创建新集群
– 点击“Create Cluster”按钮。
– 选择适合需求的配置(如性能模式、区域位置等)。
– 输入集群名称,并确认创建。等待集群启动
创建完成后,Qdrant 将分配一个托管的集群实例。可以在控制台中查看集群的状态和详细信息。
3. 获取 API 密钥和连接信息
API 密钥
在 Qdrant Cloud 控制台中,找到集群详情页面,复制生成的 API 密钥。这个密钥用于身份验证。主机地址
同样在集群详情页面中,您可以找到分配给您的 主机地址(例如:`https://your-cluster-id.aws.qdrant.cloud`)。这是与 Qdrant 集群交互的入口。 -
2025-04-01 - 12:03 #128244
追光参与者3. 向量数据库
向量数据库(Vector Database)用于存储、索引和高效检索 高维向量,常用于 语义搜索、推荐系统、异常检测 等场景。例如,文本、图像、音频都可以转换为向量,以便进行相似性搜索。将数据转换为 嵌入向量,嵌入向量存储与检索。Pinecone 和 Qdrant 进行对比,选择更适合你的 向量数据库需求?
两者都是 高效的向量数据库,但它们有一些关键区别:
Pinecone vs. Qdrant 对比
特性
Pinecone
Qdrant
部署方式
云端 SaaS(Pinecone 提供托管)
本地部署 / 自托管(Docker, Bare Metal)
存储格式
向量存储(索引自动管理)
向量 + 元数据(可定制索引)
索引技术
HNSW(自动管理)
HNSW(可自定义参数)
查询方式
仅向量搜索
向量 + BM25 关键词搜索
多维度支持
需要单独索引不同维度的向量
可以存储不同维度的向量(如 768、1024、1536、3572)
可扩展性
自动扩展,适用于大规模应用
需要手动扩展,但控制权更强
访问控制
API Key 认证
API Key 或 自定义身份验证
适合场景
商业 SaaS,简单集成
需要自定义,部署灵活
向量数据库在进行 近似最近邻搜索(ANN) 时,通常需要计算向量间的相似度。以下是几种常见的相似度度量方式:
1. 余弦相似度(Cosine Similarity)
特点:衡量两个向量的方向是否相似(角度越小,相似度越高),适用于文本搜索、推荐系统(例如嵌入模型生成的文本向量).2. 欧几里得距离(Euclidean Distance)
特点:衡量两点间的直线距离;适用于 像检索、空间数据分析
3. 曼哈顿距离(Manhattan Distance / L1 距离)
特点:适用于高维稀疏数据(如推荐系统中的用户行为数据) -
2025-03-17 - 13:55 #128202
追光参与者FRPC批量端口号代理与泛域名解析配置方法
这个配置文件是 Frp 客户端(frpc) 配置的一部分,使用了 Go 模板语法 来生成多个代理配置。它的作用是根据 端口范围 来动态生成多个 TCP 代理。接下来,我将详细解释每个部分:
parseNumberRangePair 是一个自定义函数(假设是为了处理端口范围),将字符串 “888-999” 转换为一个端口范围。例如,888到 999。
•第一个参数 “888-999” 是表示端口范围的字符串。
•第二个参数 “888-999” 是备用参数或者用于其他配置逻辑。
•range 是 Go 模板的关键字,允许遍历 parseNumberRangePair 返回的结果。这使得我们能够为端口范围内的每个端口动态生成代理配置。# frpc.toml {{- range $_, $v := parseNumberRangePair "888-999" "888-999" }} [[proxies]] name = "Jisongbin-{{ $v.First }}" type = "tcp" localIP = "127.0.0.1" localPort = {{ $v.First }} remotePort = {{ $v.Second }} transport.useEncryption = true transport.useCompression = true {{- end }}泛域名解析
在这个配置中,主要的作用是设置 Frp 客户端(frpc) 中的反向代理,特别是通过 泛域名解析 来映射本地服务。自定义域名(customDomains),这行配置特别重要,因为它涉及到 泛域名解析(Wildcard DNS)。*.xxx.com 表示匹配 所有 以 xxx.com 结尾的子域名。使用这个配置后,Frp 会接收所有 xxx.com 下的子域名请求,它们都会被转发到本地服务上。当使用大量子域名的情况,使用泛域名解析非常方便。
[[proxies]] name = "xxx" type = "http" localPort = 80 localIP = "198.19.249.118" transport.useEncryption = true transport.useCompression = true customDomains = ["*.x.xxx.com"] -
2025-03-04 - 15:22 #128141
追光参与者各产商的大模型部署并在工作中投入生产使用的大模型选择
这里的测试方面的数据为硬件平台直接输出,而感受与总结方面尽可能做到客观,但难免会有主观之处:
1、除了deepseek开源,还有其他开源大模型么
deepseek是公开发布并可以下载的模型,开源对我们来说是非常有益的事情,同时我们也应关注更多的开源产商LLaMA、Qwen、Mistral,google的开源模型群,微软的、ibm等,每个产商的模型都是成千上万技术人员的劳动成果,通过各种算法集合了人类的智慧,也就决定了不同的大模型具备的核心能力也有所区别,作用用户我们要打开视野,多使用不同的模型,从计算成本、计算效率、结果的可靠性三个方面来选择最适合我们工作流的模型。
未完待进一步补充~~
经过若干测试,对工作非常有用且效率非常高的模型,M1 pro 16GB即可流畅运行:
1、claude-3-5-sonnet-20241022-GGUF:Claude 3.5 Sonnet 在自然语言理解(NLU)和生成(NLG)方面表现出色,能够处理复杂问题、生成高质量文本,并支持多语言。当然众所周知,Claude在代码编写方面的巨大潜力,使用它来进行代码写作是非常好的选择。在M芯片上有着出色的性能表现。
16.43 tok/sec•990 tokens•14.87s to first token•Stop reason: User Stopped
2、Qwen2.5-14B-Instruct-4bit:支持苹果的MLX框架,专为 Apple Silicon优化。 是阿里巴巴通义千问系列中的一个优化版本,专为高效推理和低资源消耗设计。它基于 Qwen2.5-14B 模型,经过量化处理(4-bit 量化),在保持高性能的同时显著降低了硬件需求,适合在资源受限的环境中部署。
17.27 tok/sec • 488 tokens•29.33s to first token•Stop reason: EOS Token Found
3、Mistral-Nemo-Instruct-2407-4bit:支持苹果的MLX框架,专为 Apple Silicon优化。是由 Mistral AI 开发的一系列先进语言模型中的一个优化版本,专注于高效推理和低资源消耗。该模型基于 Mistral 的基础架构,并通过量化技术(4-bit 量化)进行了优化,使其能够在资源受限的环境中运行,同时保持高性能。
24.77 tok/sec•231 tokens•1.27s to first token•Stop reason: EOS Token Found
4、Meta-Llama-3.1-8B-Instruct-4bit:支持苹果的MLX框架,专为 Apple Silicon优化。是由 Meta 开发的 Llama 系列语言模型中的一个优化版本,专注于高效推理和低资源消耗。该模型基于 Llama 3.1 架构,经过指令微调(Instruct-tuning)优化,并通过 4-bit 量化技术进一步压缩,使其能够在资源受限的环境中运行,同时保持较高的性能。
36.08 tok/sec•949 tokens•0.51s to first token•Stop reason: User Stopped
5、Llama-3.2-11B-Vision-Instruct-4bit:支持苹果的MLX框架,专为 Apple Silicon优化。是由 Meta 开发的多模态语言模型,基于 Llama 系列的最新版本(Llama 3.2),专注于高效推理和低资源消耗。该模型结合了文本理解和视觉处理能力,能够处理图像和文本的多模态任务。通过 4-bit 量化技术优化,它能够在资源受限的环境中运行,同时保持较高的性能。在M1pro芯片上运行效率很慢,但是对图片的理解能力很强,适合分析图片,虽然速度慢,但也能满足一般需求。
6、Phi-4:是由 Microsoft Research 开发的一系列小型语言模型(Small Language Models, SLMs)中的最新版本。Phi 系列模型专注于在较小的参数规模下实现高性能,特别适合资源受限的环境和特定任务优化。Phi-4 在继承前代模型优势的基础上,进一步提升了性能、效率和适用性。
7、Gemma-2-9B-IT-4bit:支持苹果的MLX框架,专为 Apple Silicon优化。是由 Google 开发的一系列紧凑型语言模型中的优化版本,专注于高效推理和低资源消耗。该模型基于 Gemma 2 架构,经过指令微调(Instruction Tuning, IT)优化,并通过 4-bit 量化技术进一步压缩,使其能够在资源受限的环境中运行,同时保持较高的性能。
28.55 tok/sec•88 tokens•1.09s to first token•Stop reason: EOS Token Found
-
2025-03-04 - 15:11 #128139
追光参与者在Mac M1pro上使用lm studio和ollama的感受
1、效率与速度
LM Studio使用GGUF模型比Ollama反应速度更快20%,如果在LM Studio中使用苹果M芯片框架的MLX比GGUF还要快30%,在效率和配置效率方面LM Studio更高效。拿DeepSeek R1:14B执行相同的任务来说
在Ollama上达到,9.34 tokens/s,在LM Studio使用GGUF:13.4 tokens/s,而MLX可以达到18.43 tokens/秒。此外,LM Studio的内存占用也比Ollama低,尤其是在处理大规模数据时,LM Studio的内存占用会更少,这使得它在处理大规模数据时更加高效。
2、配置与api远程调用扩展方面
Ollama的生态非常成熟,比如通过FRPS内网映射到外网在WordPress等网站、应用中调用,Ollama配套的组件丰富,很容易就可以实现对接。
如果想要将部署好的模型从内网发布到公网,可以参照我以前写过的文章,也都是我自己部署的记录:
LM Studio的API接口和Open AI的完全一样,也可以直接修改API.openai.com/v1等接口为自己的IP/域名实现远程API对接,需要自己动手。我将LM Studio对接到Ai Engine这个组件上,几乎是重写了整个接口才得以实现。而Ollama有已经开发过的组建,(当然需要付费)。
此外,LM Studio也支持多种API接口的扩展,包括但不限于Open AI、Google Cloud AI Platform等,这使得它可以与更多的第三方服务集成。
3、大小模型混合并行计算输出
LM Studio提供了草稿模型(Speculative Decoding)选择,包括但不限于GGUF、MLX等,这使得用户可以根据自己的需求选择合适的小模型。同时进行并行计算输出,大幅度提高运行效率。
将大模型与小模型配对。草案模型应该比主模型小得多,并且来自同一个家族。例如,您可以使用Llama 3.2 1B作为Llama 3.1 8B的草稿模型。
运行原理:草案模型会首先运行,快速预测接下来的几个tokens是“草稿”。紧接着,草稿模型生成的令牌要么被主模型确认,要么被拒绝,然后和主模型共同解决问题。
大小模型运行监测:还可以打开已处理的草稿生成的Tokens和主模型的显示,这样能显示当前的回复中哪些是从草稿模型生成,哪些是从主模型生成的。绿色越多越好。
大小模型局域网调用支持:还可以通过LM Studio的本地服务器使用Speculative Decoding,可以得到丰富的生成统计数据。
总而言之,LM Studio和Ollama都有其优点和缺点。需要根据自己的需求选择合适的工具,当然如果硬件是M芯片的,首选MLX,要让计算速度快一点,硬件投入是巨大的。
-
2025-04-28 - 14:09 #128476
追光参与者这涉及到整个Pipeline构建,多种软件之间协同,数据传递,多方面的生产线构建问题,单纯靠现有软件原始功能不能实现。等将来我们做Pipeline方面教程和服务时候,会陆续发布出来。
这里的话题中有详细讲解了从原始素材到最终剪辑的流程:
合成的流程—反求摄像机—摄像机导入到三维软件—–最终合成—-剪辑。先合成,最后再来剪辑,就能保持正常的节奏啦~~ -
2025-04-27 - 19:31 #128470
-
2025-04-27 - 12:44 #128463
追光参与者4S会自动停止,意味着卡的速度低于内存中的数据需要写入的速度,然后内存满了。
这个速度是卡的速度限制,卡的速度即使是最快的卡,也达不到机器的速度。还可以设置分辨率的裁切比例,帧速率,分辨率来选取一个适合自己配置的设置,另外卡的真实速度和标称速度要实际测试。实际写入速度需要大于100MB/s,可以用大文件拷入进行测试。
比如我的5D3的机器,标配的卡录制2秒就停了,换了雷克沙的高速卡,单镜头能达到4分钟就已经足够使用了,一个镜头一个镜头的拍。Raw的视频包含元数据非常大。我的配置不到20分钟的镜头,64GB卡就满了。
Raw视频适合高标准,有着严格拍摄脚本的广告、剧情一类的制作,不太适合即兴拍摄,因为后期流程也和胶片差不多。适合像拍电影一样的拍,每个镜头都思考好了再开始,很像胶片拍摄的流程。
-
2025-04-27 - 11:35 #128459
追光参与者MLV.App功能强大,界面清晰,更新速度非常快,更加符合现代化的制作方式。MlRawViewer是最早期的制作人拍摄Raw视频的方式,制作方式更加传统,比如默认导出为DNG序列,然后在AE或者达芬奇中进行处理。
魔灯具有自己独立的网格模式,需要在魔灯菜单里面设置,当然还有更多佳能官方没有的模式,包括峰值对焦之类,可以从社区内菜单的翻译上查看更多功能,我比较常用的是延迟拍摄、峰值对焦、还有低帧速率视频。和佳能的网格模式相当于是俩个不同的操作系统,不可以混用。
-
2025-04-25 - 08:46 #128454
追光参与者你好,本篇文章讲述的就是如何直接将3DEqualizer计算好的畸变数据作为一个独立的节点,直接传输给Nuke,而不需要进行渲染。如果非要渲染出来作为参考视频导入到三维软件进行对位测试,在nuke中渲染即可。
可以采用这样的流程:
3DEqualizer—-导出畸变数据到Nuke—-导出去除畸变的素材给三维软件参考使用
三维软件中输出制作好的匹配模型动画—-导出模型或者渲染图—-导入到Nuke—-添加3DEqualizer畸变。这样即可让三维渲染保持和原始视频一致的畸变,更加真实。
-
2025-03-20 - 17:24 #128206
追光参与者是可以追踪定机位的,技术流程请参考这一篇:
如果在反求镜头追踪的同时,还需要追踪车辆轨迹,可以使用复合追踪流程:
另外不管是PFtrack还是3DEqualizer都可以导出选择的物体为坐标数据,TXT文本。我以前用这个方法交换不同软件的追踪数据。但是要注意,不同软件的位置标记记录算法比例可能不同。
-
-
作者帖子